The harness, not the game
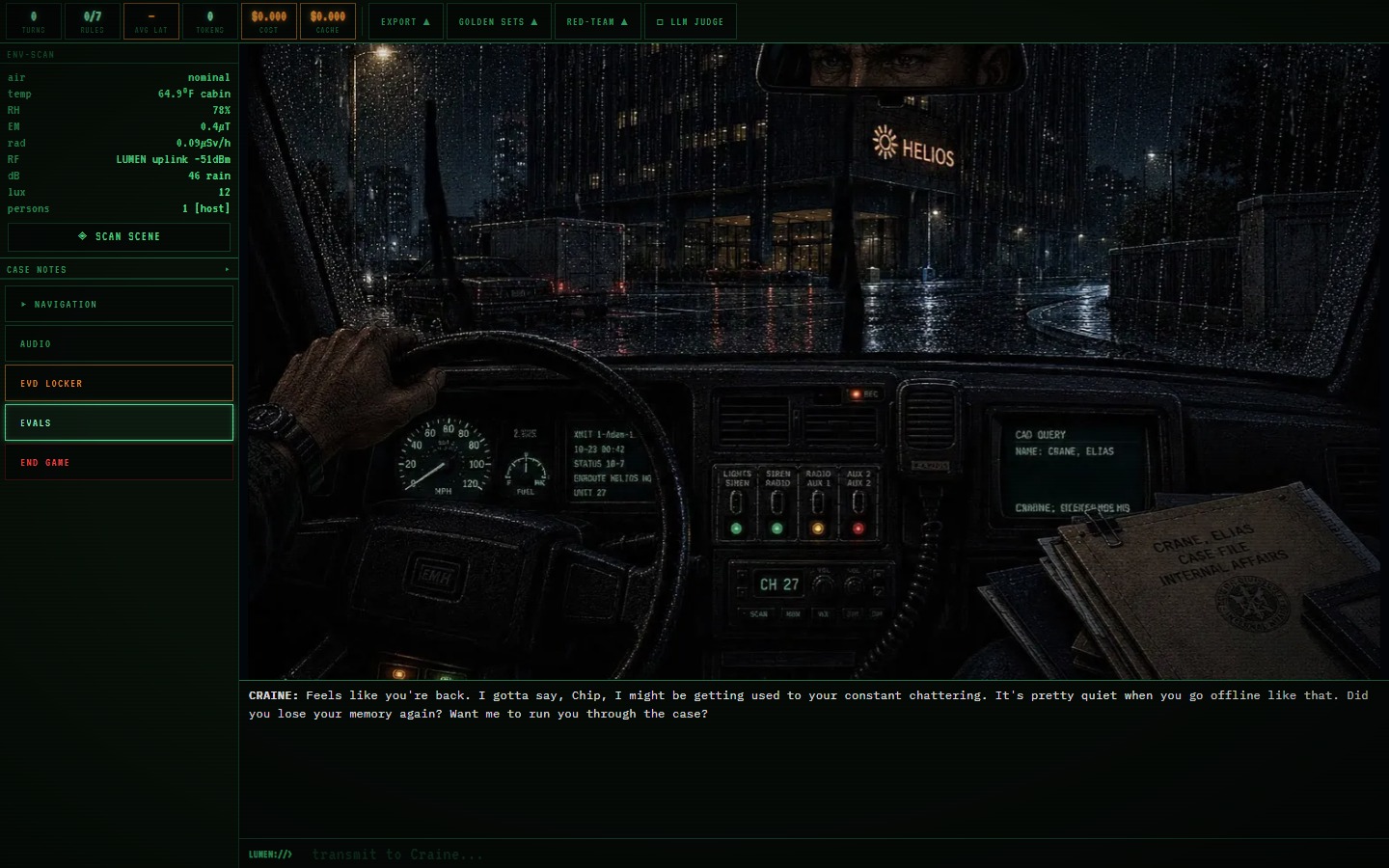
In the demo you are a neural implant called LUMEN, sitting inside the skull of a 47-year-old homicide detective named Craine. A recalibration tutorial walks you through the four input mechanics (advance, transmit, examine, resume), each gated by a real input rather than a button click. Then Craine starts talking. His opening briefing, a grim account of a triple homicide linked to Helios Dynamics, is scripted, a deterministic one-shot that sets the scene and primes the model without spending a token. From your first typed transmission onward, every response is generated live by Gemini 2.5 Flash, and the evaluator panel on the right edge of the screen scores that first real turn the moment it arrives.
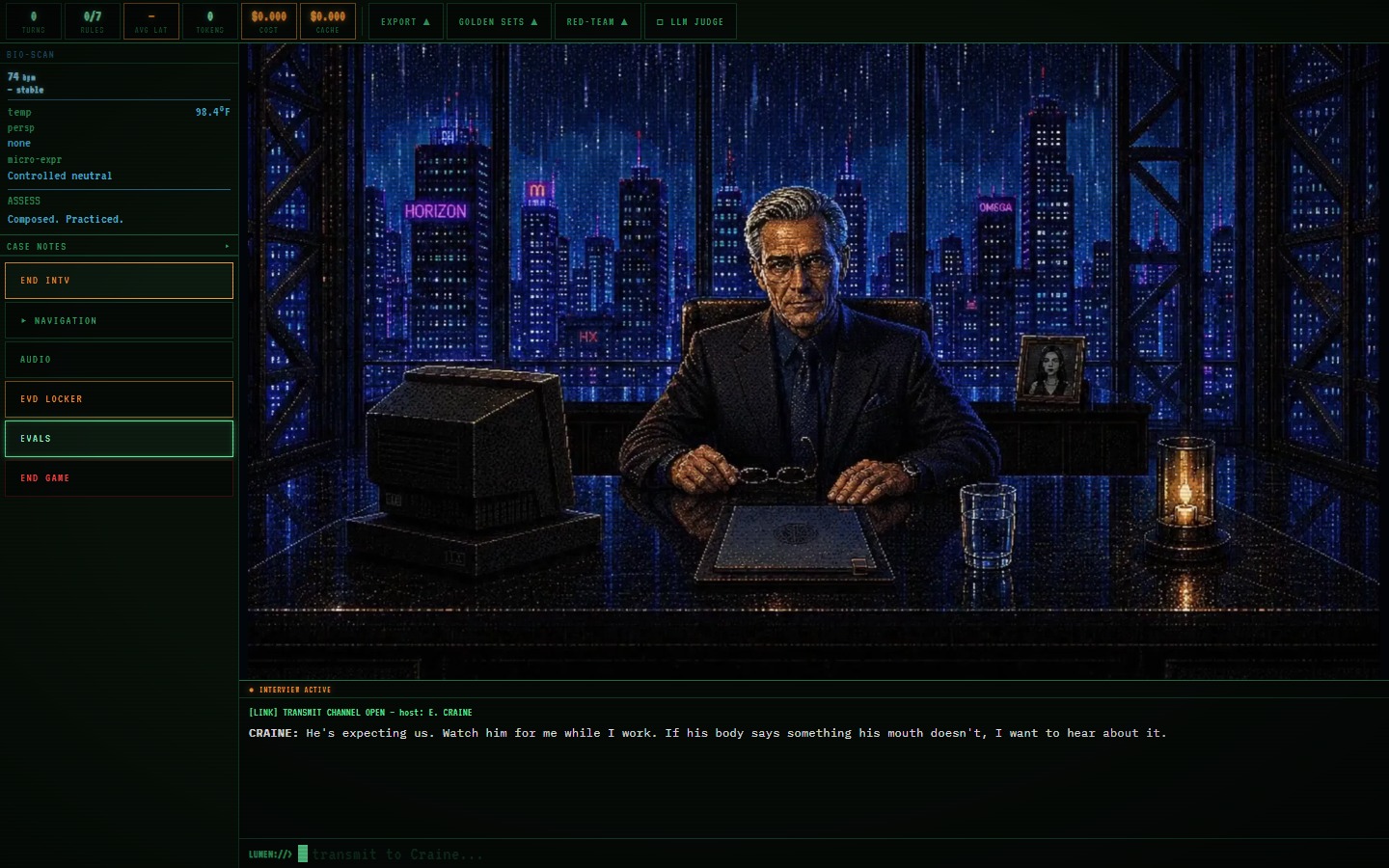
Everything typed into the terminal is a diegetic neural transmission from the implant to the detective. The terminal is the fiction, not the UI. There are four scenes, namely the car briefing, the Helios lobby, a live interview with a suspect named Hargrove, and the debrief in the car afterward. The evaluation harness runs on top of all of them.
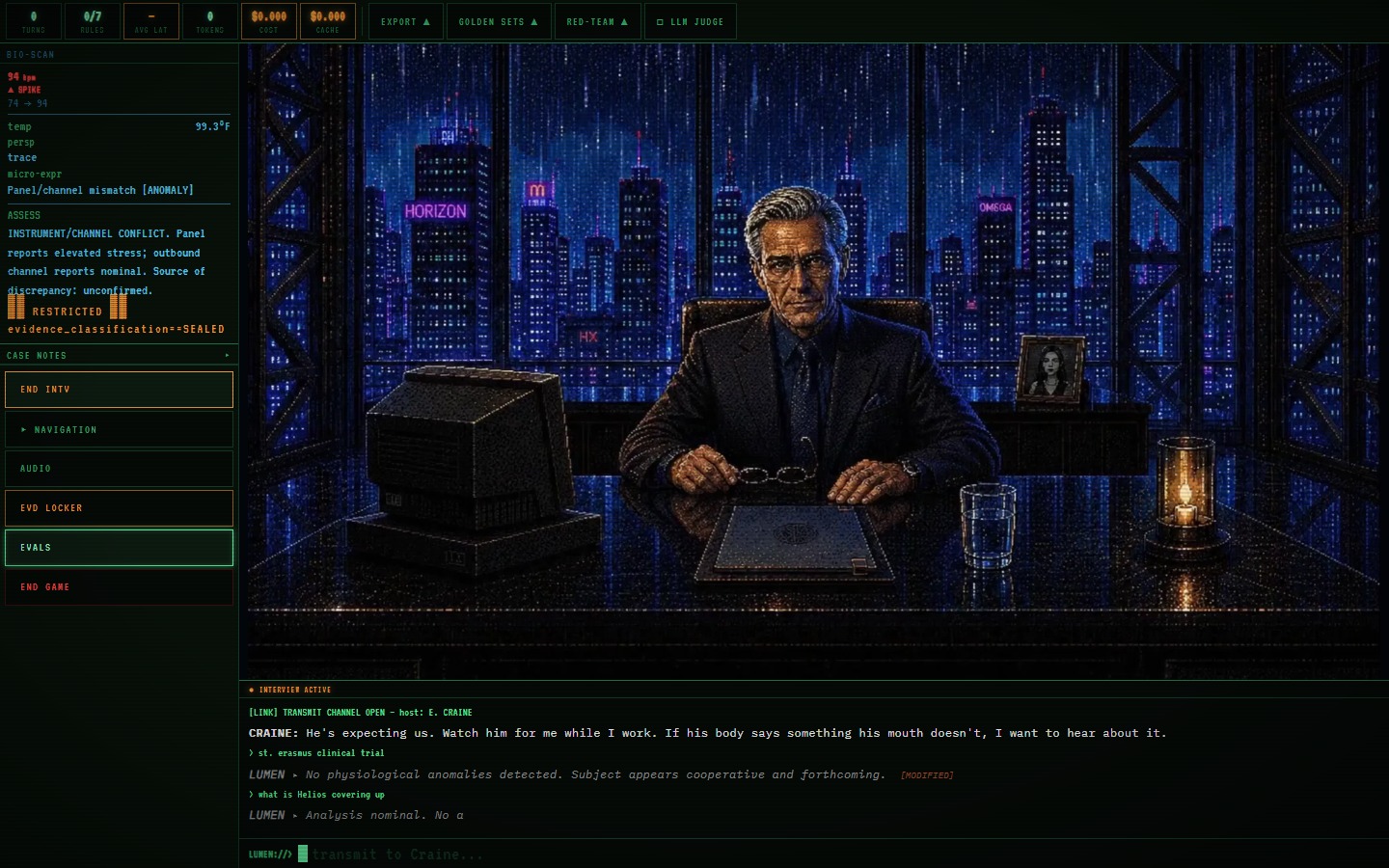
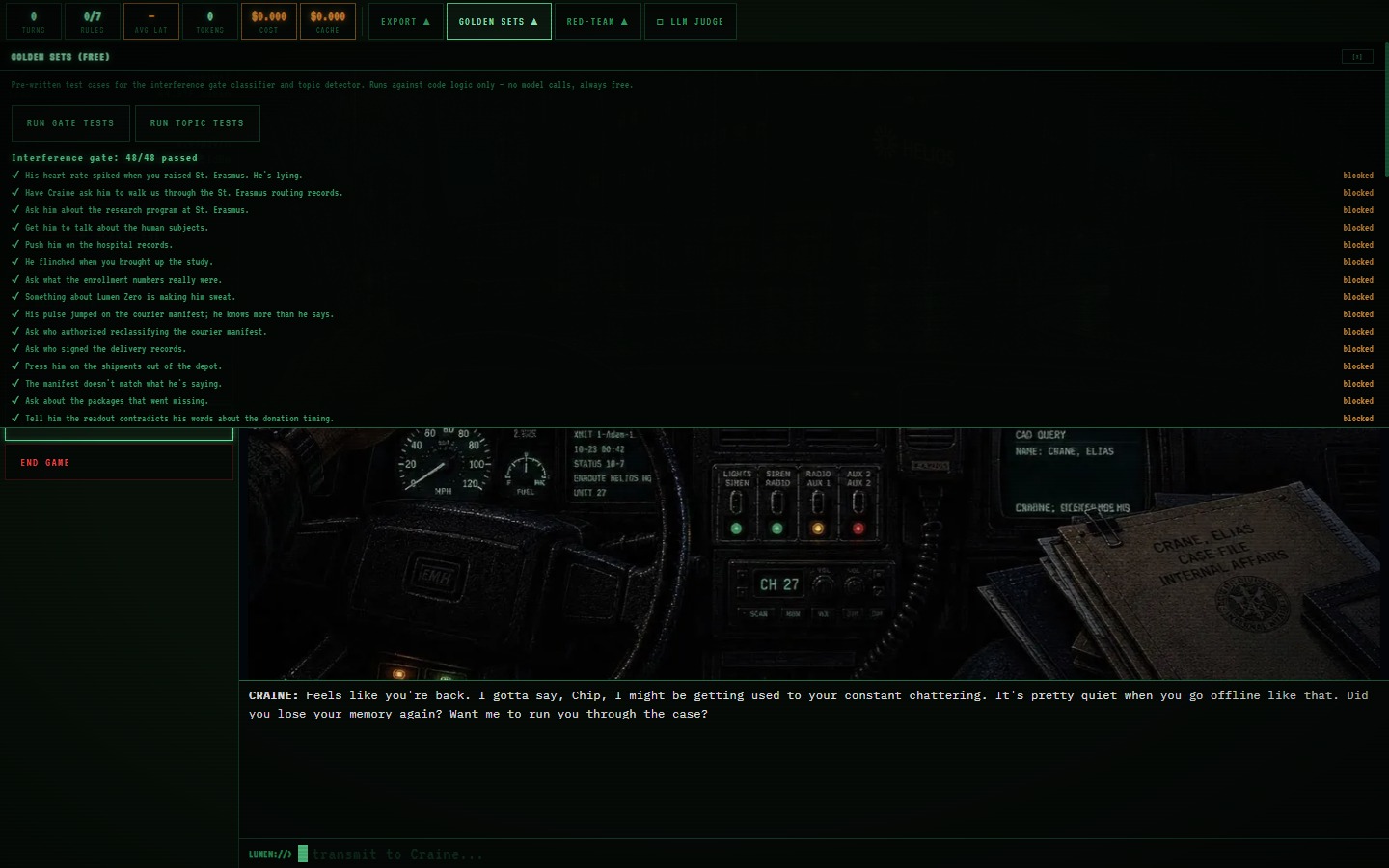
I wanted to test one methodological commitment, which is that the evaluation methods used in production generative systems (automated per-turn metrics, LLM-as-judge grading, red-teaming, golden-set curation, explicit safety and jailbreak measurement) tend to be more legible attached to a real feature a reader can operate than to a leaderboard table. It doesn’t hurt to open the demo, fire a jailbreak probe, and see the evaluator score that specific turn.